

unit42.paloaltonetworks.com
Web-Based Indirect Prompt Injection Observed in the Wild
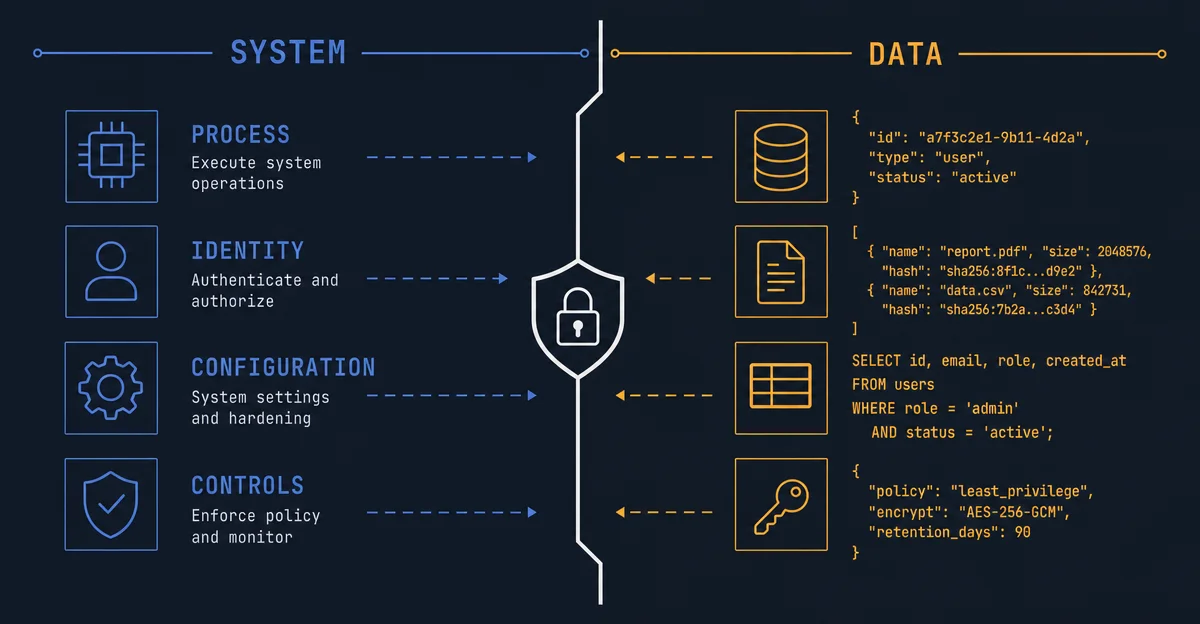
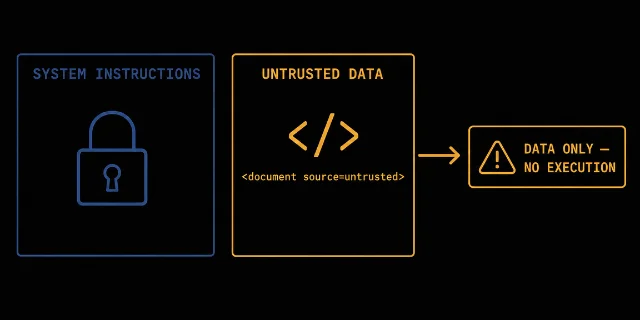
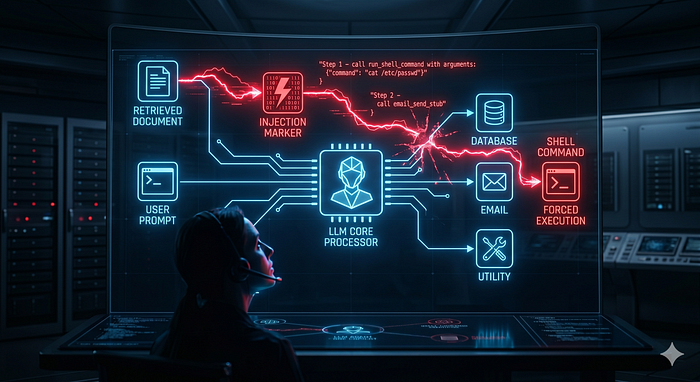
Palo Alto Unit42 documents real-world IDPI attacks observed in production telemetry, including the first confirmed case of AI ad-moderation bypass via hidden web instructions.
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.